9 Probability Distributions for Representing Priors and Data Generation
In this chapter, we move beyond
9.1 Normal Distribution
The
More details for the
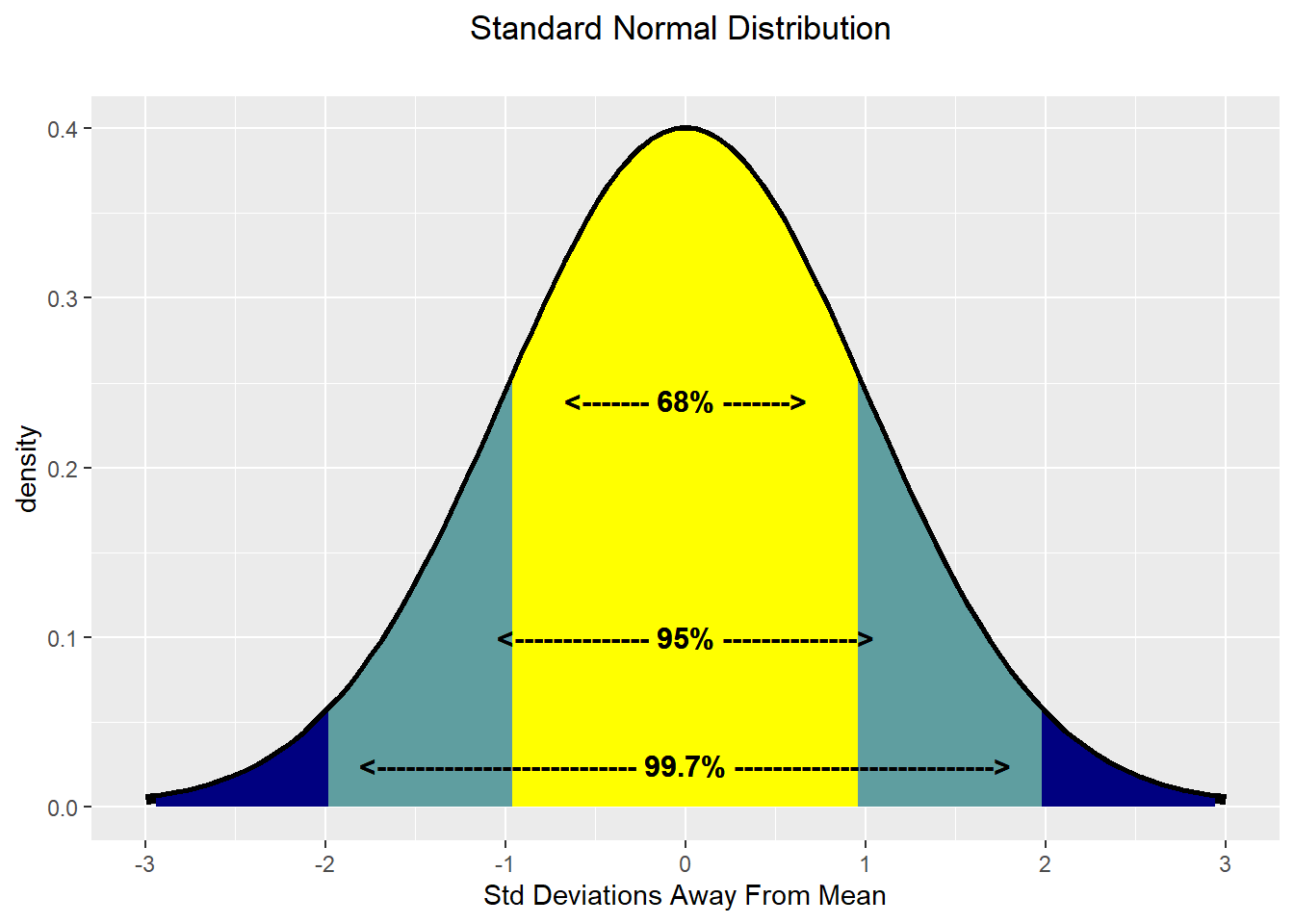
There is an astounding amount of data in the world that appears to be normally distributed. Here are some examples:
- Finance: Changes in the logarithm of exchange rates, price indices, and stock market indices are assumed normal
- Testing: Standardized test scores (e.g. IQ, SAT Scores)
- Biology: Heights of males in the united states
- Physics: Density of an electron cloud is 1s state.
- Manufacturing: Height of a scooter’s steering support
- Inventory Control: Demand for chicken noodle soup from a distribution center
Due to its prevalance and some nice mathematical properties, this is often the distribution you learn the most about in a statistics course. For us, it is often a good distribution when data or uncertainty is characterized by diminishing probability as potential realizations get further away from the mean. Given the small probability given to outliers, this is not the best distribution to use (at least by itself) if data far from the mean are expected. Even though mathematical theory tells us the support of the
Here is just a sample of three normal distributions:
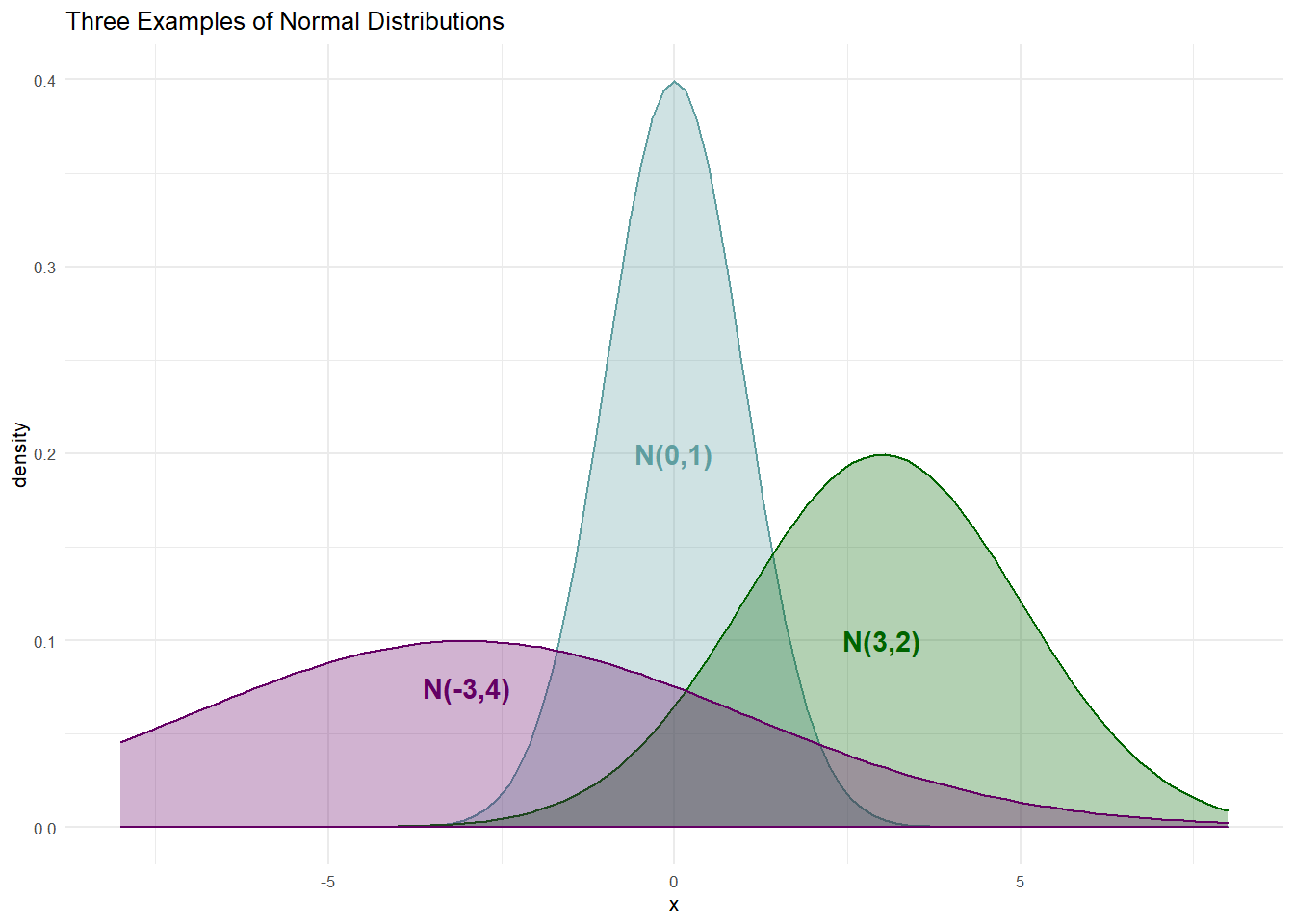
The densities of Figure 9.2 show the typical bell-shaped, symmetric curve, that we are used to. Since the
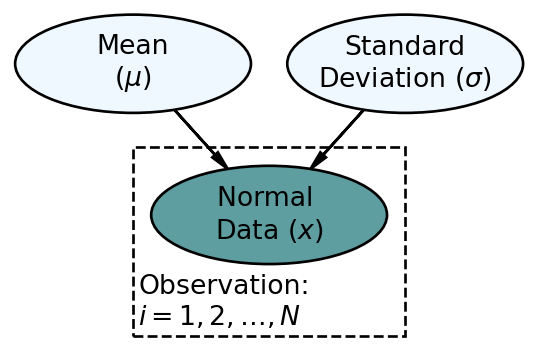
and the statistical model with priors:
where the prior distributions get determined based on the context of the problem under study.
For example, let’s say we are interested in modelling the heights of cherry trees. Even if we do not know much about cherry trees, we can probably be 95% confident that they are somewhere between 1 foot and 99 feet. Hence, we can set up a prior with 95% probability between 1 and 99, i.e. if
Choosing a prior on
Hence, our statistical model becomes:
After choosing our prior, we then use data to reallocate plausibility over all our model parameters. There is a dataset available with this book of cherry tree heights:
## get cherry tree data
import pandas as pd
import xarray as xr
import numpy as np
# Source: Ryan, T. A., Joiner, B. L. and Ryan, B. F. (1976)
# The Minitab Student Handbook. Duxbury Press.
## This data set provides measurements of the diameter (girth), height,
## and volume of timber in 31 felled black cherry trees.
url = "https://raw.githubusercontent.com/flyaflya/persuasive/main/trees.csv"
treesDF = pd.read_csv(url)
## make tree height an array
## numpyro will NOT accept a pandas series as input
treeHeightData = treesDF.Height.to_numpy() # series to numpy arraywhich we can use to create code to get a posterior. Using numpyro, we get our representative sample of the posterior distribution:
import numpyro
import numpyro.distributions as dist
from jax import random
from numpyro.infer import MCMC, NUTS
import arviz as az
## make tree height an array - numpyro will NOT accept a pandas series as input
treeHeightData = treesDF.Height.to_numpy() # series to numpy array
## define the graphical/statistical model as a Python function
def cherryTreeModel(x):
# loc – mean of the distribution (often referred to as mu)
# scale – standard dev. of the distribution (often referred to as sigma)
mu = numpyro.sample('mu', dist.Normal(loc = 50, scale = 24.5))
sigma = numpyro.sample('sigma', dist.Uniform(low = 0, high = 50))
with numpyro.plate('observation', len(x)):
x = numpyro.sample('x', dist.Normal(loc = mu, scale = sigma), obs=x)
# ## computationally get posterior distribution
mcmc = MCMC(NUTS(cherryTreeModel), num_warmup=1000, num_samples=4000)
rng_key = random.PRNGKey(seed = 111) ## so you and I get same results
mcmc.run(rng_key, x=treeHeightData) ## get representative sample of posteriordrawsDS = az.from_numpyro(mcmc).posterior ## get samples into xarrayAnd then, plot the credible values using the plot_posterior() function from the arviz package. The posterior distribution provides representative samples of all unobserved parameters in the model. For each parameter, the 94% highest density interval (HDI) is presented (94% is a changeable default). This interval represents the smallest interval such that 94% of all sample draws fall within the range of values spanned by the horizontal black line. The numbers above the black line are rounded approximations for the interval boundaries. The hdi function could yield exact results:
az.hdi(drawsDS,hdi_prob = 0.94)<xarray.Dataset>
Dimensions: (hdi: 2)
Coordinates:
* hdi (hdi) <U6 'lower' 'higher'
Data variables:
mu (hdi) float64 73.61 78.21
sigma (hdi) float64 5.141 8.527where we see plausible values for expected cherry tree height
REMINDER: the posterior distribution for the average cherry tree height is no longer normally distributed and the standard deviation is no longer uniform. This is a reminder that prior distribution families do not restrict the shape of the posterior distribution.
We now have insight as to the height of cherry trees as our prior uncertainty is significantly reduced. Instead of cherry tree heights averaging anywhere from 1 to 99 feet as accommodated by our prior, we now say (roughly speaking) the average height is somewhere in the 74-78 foot range. Instead of the variation in height of trees being plausibly as high as 50 feet, the height of any individual tree is most likely within 10-17 feet of the average height (i.e.
9.2 Gamma Distribution
The support of any random variable with a normal distribution is
More details for the
The numpyro uses the term concentration parameter) and numpyro expects these two parameters when using a
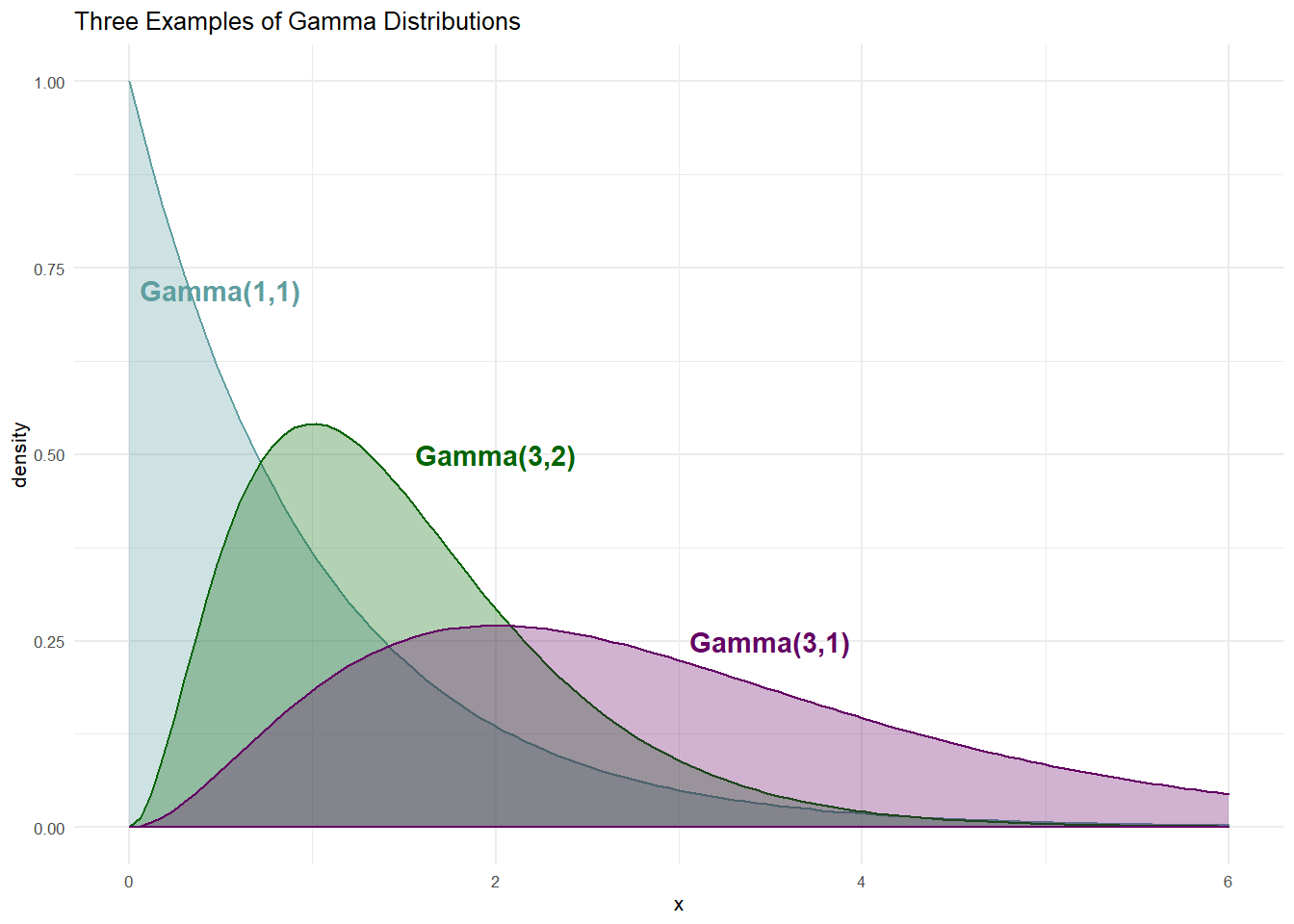
When choosing
The Gamma distribution is a superset of some other famous distributions. The
These properties will be demonstrated when the gamma is called upon as a prior in subsequent sections.
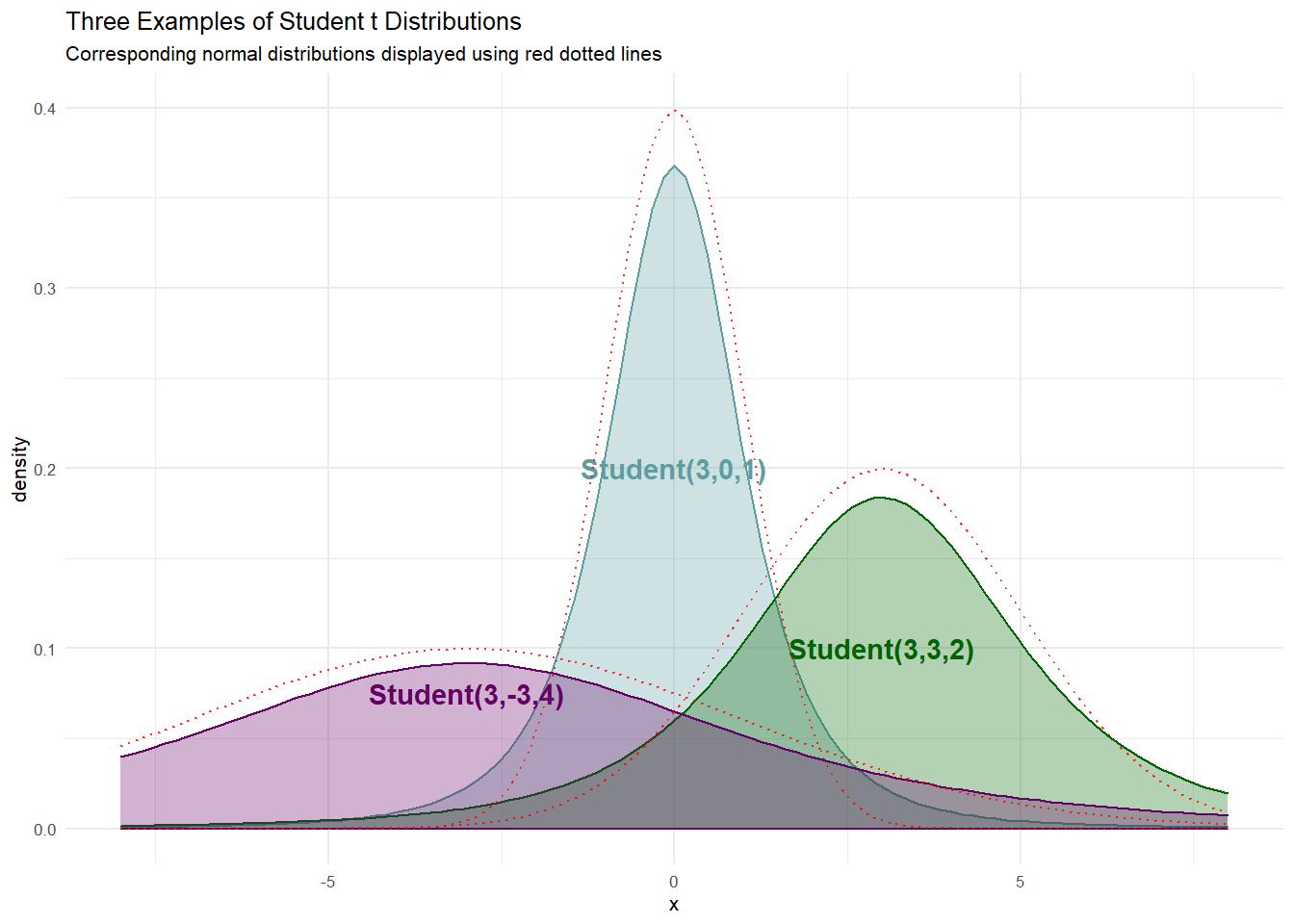
9.3 Student t Distribution
For our purposes, the
The numpyro, is a three parameter distribution; notated loc) and scale), can be interpreted just as they are with the normal distribution. The first parameter, numpyro as df), refers to the degrees of freedom. Interestingly, as
Here is a sample of three student-t distributions:
If we wanted to model the cherry tree heights using a
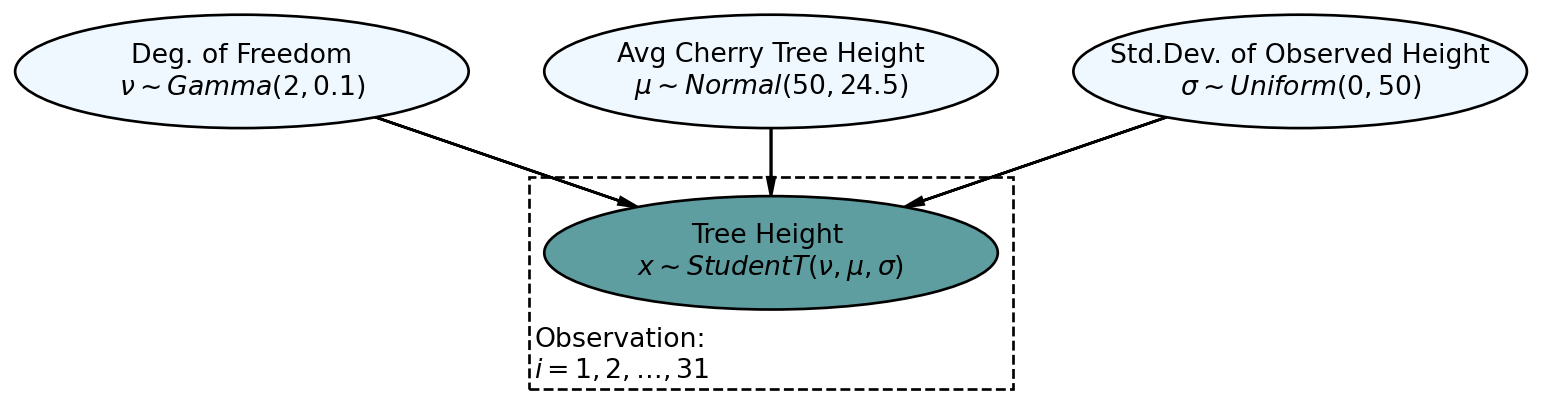
Using numpyro, we get our representative sample of the posterior:
## define the generative DAG as a Python function
def cherryTreeModelT(x):
# df - degrees of freedom (often referred to as nu)
# loc – mean of the distribution (often referred to as mu)
# scale – standard dev. of the distribution (often referred to as sigma)
nu = numpyro.sample('nu', dist.Gamma(concentration = 2, rate = 0.1))
mu = numpyro.sample('mu', dist.Normal(loc = 50, scale = 24.5))
sigma = numpyro.sample('sigma', dist.Uniform(low = 0, high = 50))
with numpyro.plate('observation', len(x)):
x = numpyro.sample('x', dist.StudentT(df = nu,
loc = mu,
scale = sigma),
obs=x)
# ## computationally get posterior distribution
mcmc = MCMC(NUTS(cherryTreeModelT), num_warmup=1000, num_samples=4000)
rng_key = random.PRNGKey(seed = 111) ## so you and I get same results
mcmc.run(rng_key, x=treeHeightData) ## get representative sample of posteriordrawsDS = az.from_numpyro(mcmc).posterior ## get posterior samples into xarrayAnd then, plot the credible values to observe very similar results, at least for
az.plot_posterior(drawsDS)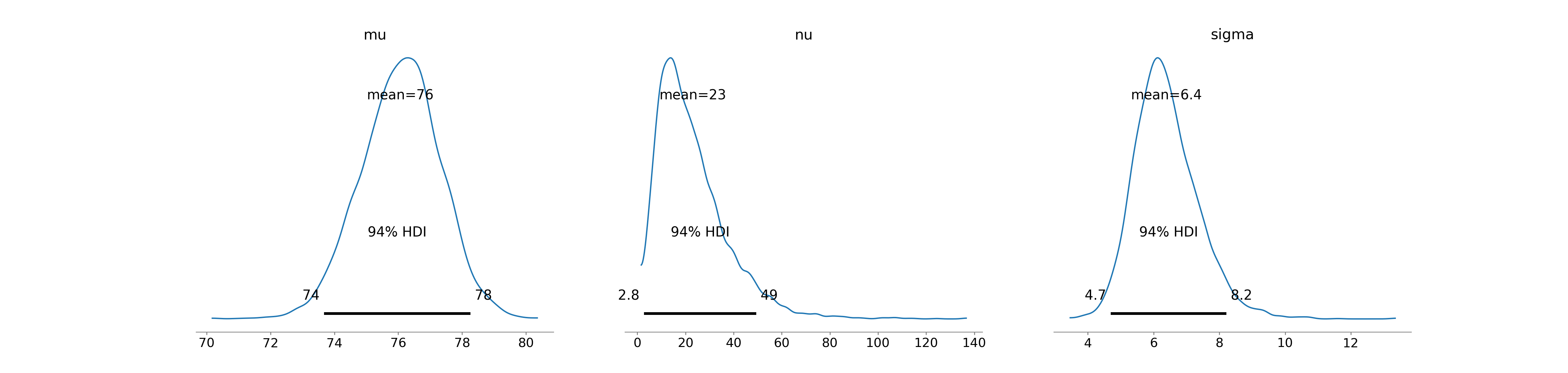
The wide distribution for
9.3.1 Robustness Of Student t Distribution
To highlight the robustness of the treeHeightDataWithOutlier = np.append(treeHeightData,1000)). Figure 9.8 shows recalculated posterior densities for both the normal and student t priors.
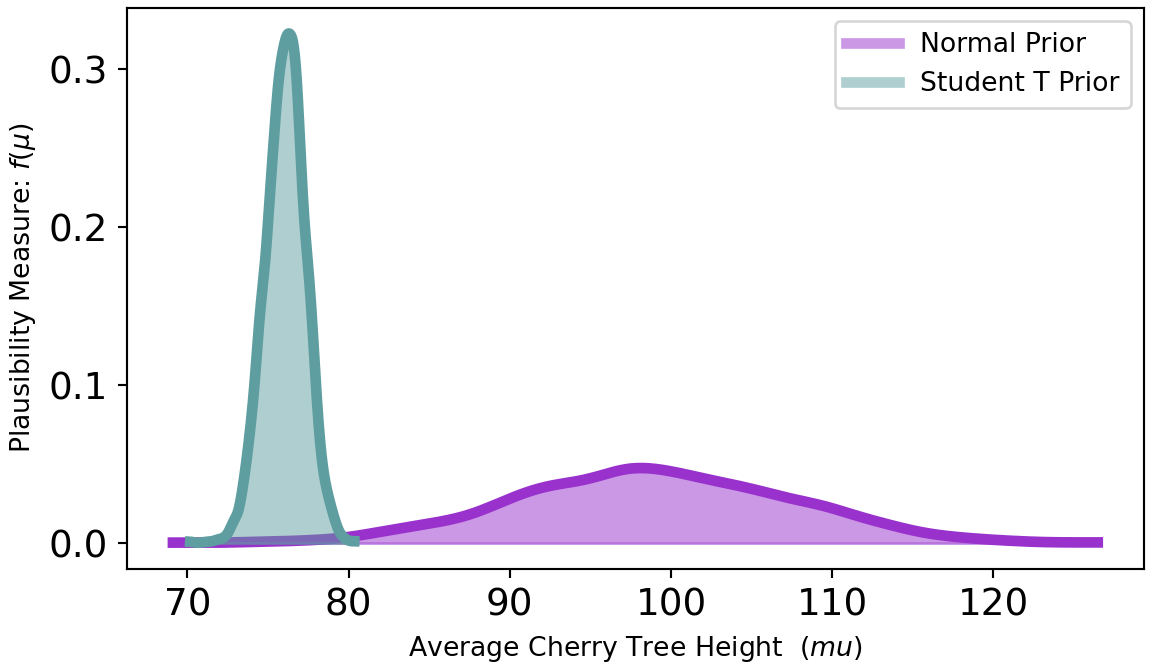
As seen in Figure 9.8, the posterior estimate of the mean
9.4 Poisson Distribution
The Poisson distribution is useful for modelling the number of times an event occurs within a specified time interval. It is a one parameter distribution where if
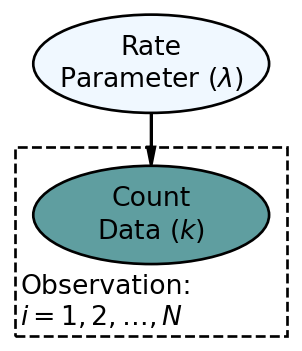
and a prior for
There are several assumptions about Poisson random variables that dictate the appropriateness of modelling counts using a Poisson random variable. Three of those assumptions are: 1)
url = "https://raw.githubusercontent.com/flyaflya/persuasive/main/tickets.csv"
ticketsDF = pd.read_csv(url, parse_dates = ["date"])
ticketsDF.head(5) precinct date month_year daily_tickets
0 1 2014-01-01 01-2014 17
1 1 2014-01-02 01-2014 67
2 1 2014-01-03 01-2014 17
3 1 2014-01-04 01-2014 42
4 1 2014-01-05 01-2014 54Let’s use the above data to look at tickets issued only on Wednesdays in New York City, and then we will model the rate of ticketing on Wednesdays using the Poisson likelihood with appropriate prior. Our restriction to Wednesday is based on our knowledge that there may be daily fluctuations in ticketing rates; for example, maybe weekends are slower ticketing days. By restricting our analysis to one day of the week, we have a better chance at conforming to the assumption of a Poisson random variable that the expected rate at which events occurs is constant throughout the time period of analysis; note, the arrivals need not occur at constant intervals, just the average rate of arrival should not change.
## get count data of tickets for Wednesdays only
## aggregate data across precincts
wedTicketsDF = (
ticketsDF
.assign(dayOfWeek = lambda DF: DF.date.dt.day_name())
.where(lambda DF: DF.dayOfWeek == "Wednesday")
.dropna()
.groupby("date")
.agg(numTickets = ('daily_tickets', 'sum'))
)A quick visualization of the data, Figure 9.10, shows some outliers. This is usually not a good sign to use a Poisson distribution, but we will continue blissfully unaware of the dangers (these dangers do get corrected in the next chapter).
plt.style.use("seaborn-whitegrid")
fig, ax = plt.subplots(figsize=(6, 3.5),
layout='constrained')
ax.scatter(wedTicketsDF.index, wedTicketsDF.numTickets)
ax.set_xlabel("Date")
ax.set_ylabel("# of Tickets Issued")
ax.set_title("Tickets Issued on Wednesdays In New York City")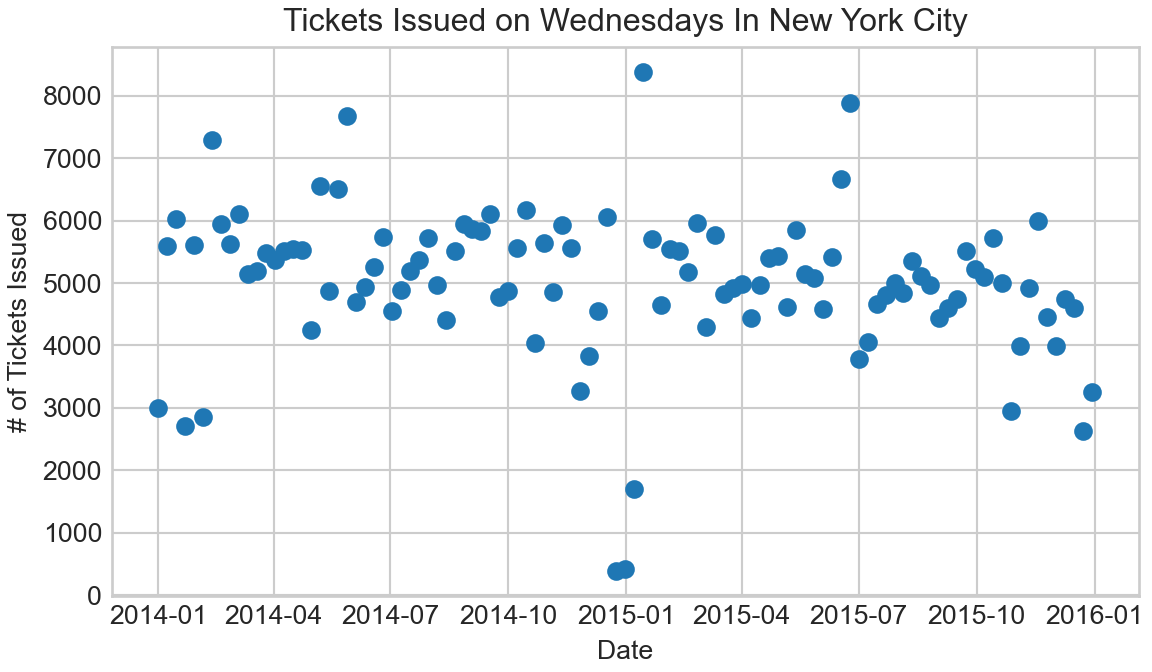
Now, we model these two years of observations using a Poisson likelihood and a prior that reflects beliefs that the average number of tickets issued on any Wednesday in NYC is somewhere between 3,000 and 7,000; for simplicity, let’s choose a
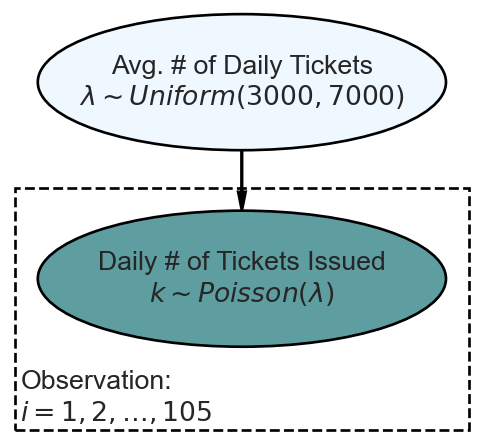
And extracting our posterior for the average rate of ticket issuance,
import xarray as xr
## make tickets data into an array - use xarray this time to show option
wedTicketsDS = xr.Dataset.from_dataframe(wedTicketsDF)
wedTickets = wedTicketsDS.numTickets.to_numpy()
## define the graphical/statistical model as a Python function
def ticketsModel(k):
## NOTE LAMBDA IS RESERVED WORD IN PYTHON... MUST USE MODIFIED NAME
lambdaParam = numpyro.sample('lambdaParam', dist.Uniform(low = 3000, high = 7000))
with numpyro.plate('observation', len(k)):
k = numpyro.sample('k', dist.Poisson(rate = lambdaParam), obs = k)
# ## computationally get posterior distribution
mcmc = MCMC(NUTS(ticketsModel), num_warmup=1000, num_samples=4000)
rng_key = random.PRNGKey(seed = 111) ## so you and I get same results
mcmc.run(rng_key, k=wedTickets) ## get representative sample of posteriordrawsDS = az.from_numpyro(mcmc).posterior ## get posterior samples into xarray
az.plot_posterior(drawsDS)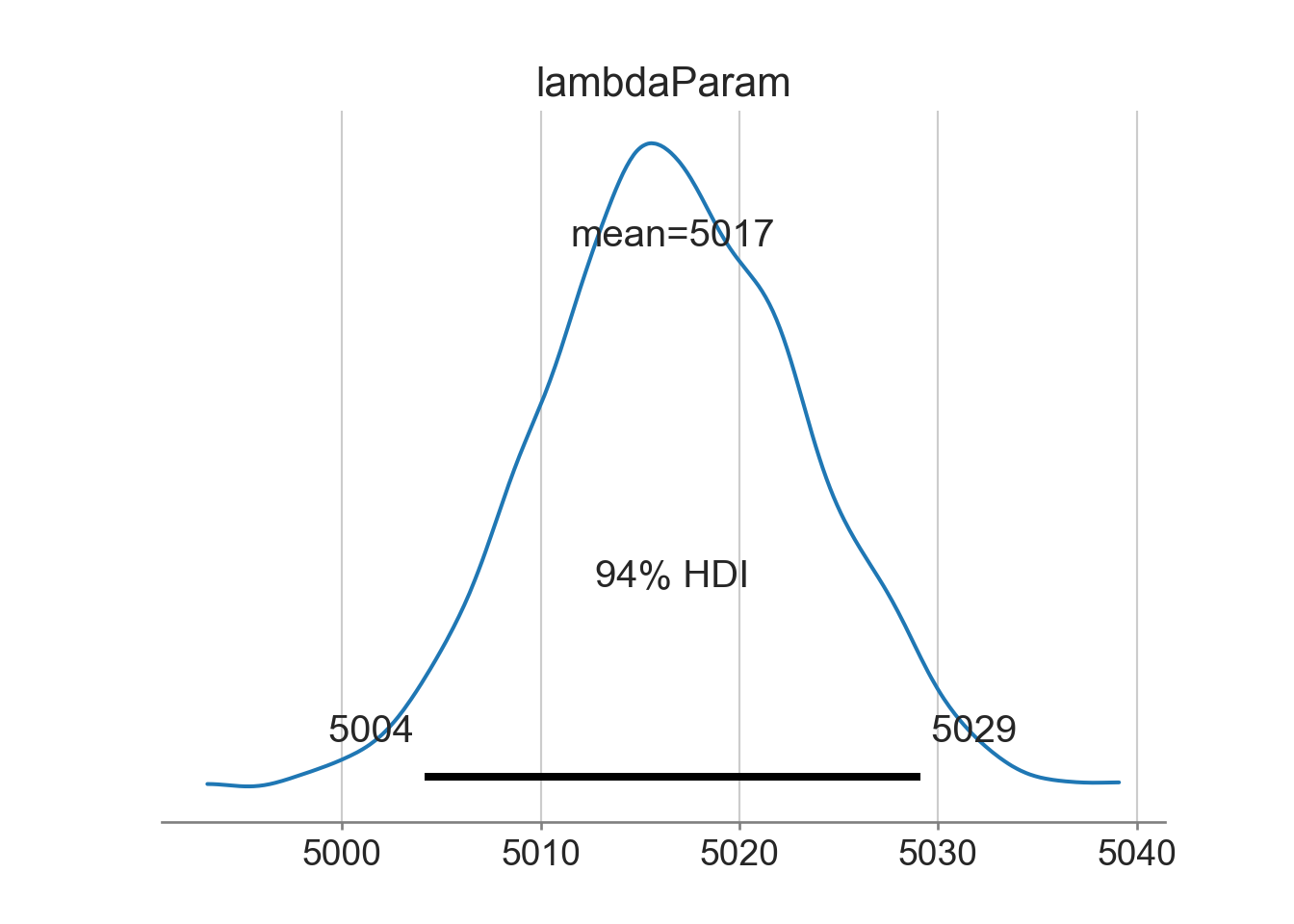
where we see that that the average rate of ticketing in NYC is slightly more than 5,000 tickets on each Wednesday. And just like always, you can use the posterior distribution to answer probabilistic queries. For example, we might want to know the probability that the average rate of ticketing is less than 5,000 (i.e.
(
drawsDS
.assign(lessThan5000Flag = lambda DS: DS.lambdaParam < 5000)
.mean()
)<xarray.Dataset>
Dimensions: ()
Data variables:
lambdaParam float32 5.017e+03
lessThan5000Flag float64 0.00625where the answer is
9.5 Getting Help
As important as it is, there is no perfect place to get information on mapping real-world phenomenon to probability distributions. Searching Wikipedia and YouTube are your best bets. After a few more chapters in this book, more complex model mappings will be accessible to you. Some of these complex modelling scenarios are available at the Stan website under case studies; the most accessible of them is this one about modelling golf putts, but it contains methods we have yet to learn. Another resource for future consumption (as it is more complex) is the Statistical Rethinking textbook with accompanying videos and translation into NumPyro code which is available here.
9.6 Questions to Learn From
See CANVAS.